Chapter 2 RMarkdown
RMarkdown is a framework that provides a literate programming format for data science. It can be used to save and execute R code within RStudio and also as a simple formatting syntax for authoring HTML, PDF, ODT, RTF, and MS Word documents as well as seamless transitions between available formats. The name “markdown” is an intentional contrast to other “markup” languages–e.g., hypertext markup language (HTML)–which require syntax that can be quite difficult to decipher for the uninitiated. One aim of the markdown paradigm is a syntax that is as human-readable as possible. “RMarkdown” is an implementation of the “markdown” language designed to accommodate embedded R code.
What is literate programming ?
Literate programming is the notion for programmers of adding narrative context with code to produce documentation for the program simultaneously. Consequently, it is possible to read through the code with explanations so that any viewer can follow through the presentation. RMarkdown offers a simple tool that allows to create reports or presentation slides in a reproducible manner with collateral advantages such as avoiding repetitive tasks by, for example, changing all figures when data are updated.
What is reproducible research ?
Reproducible research or reproducible analysis is the notion that an experiment’s whole process, including collecting data, performing analysis and producing output, can be reproduced the same way by someone else. Building non-reproducible experiments has been a problem both in research and in the industry, and having such an issue highly decreases the credibility of the authors’ findings and, potentially, the authors themselves. In essence, allowing for reproducible research implies that anyone could run the code (knit the document, etc.) and obtain the same exact results as the original research and RMarkdown is commonly used to address this issue.
Below is a short video showing a basic overview of RMarkdown.
We have created a framework application that you can use to test out different RMarkdown functions. Simply run the following code within the introDS package by using either
## Warning: package 'shiny' was built under R version 3.6.2## PhantomJS not found. You can install it with webshot::install_phantomjs(). If it is installed, please make sure the phantomjs executable can be found via the PATH variable.Then a shiny app window will pop out for you to access the application like the following:

As you can see, the toolbar on the left hand side allows you to try different RMarkdown functions. On the right hand side, Raw code shows the original R code that generates the output, Compiled html shows the compiled output based on the Raw code, and BibTex file shows the formatting lists of references.
For example, let’s try to compile some R code within RMarkdown. Click on the Code in the toolbar for some example code:

Then when we click on the Compiled html, we can see the following output:

You can also try multiple functions at the same time. For example, let’s click both Code and Emoji in the toolbar, we can see the following R code used:

The above code generates the following output:

Now you are ready to experiment different RMarkdown functions and test the corresponding outputs! 😉
2.1 Create an R Markdown file in RStudio
Within RStudio, click File → New File → R Markdown. Give the file a title and the author
(your name) and select the default output, HTML. We can change this later so don’t worry about it for the moment.

An RMarkdown is a plain text file that contains three different aspects:
- YAML metadata
- Text
- Code Chunks
2.2 YAML Metadata
YAML stands for YAML Ain’t Markup Language and is used to specify document configurations and properties such as name, date, output format, etc. The (optional) YAML header is surrounded before and after by “—” on a dedicated line.

You can also include additional formatting options such as a table of contents or even a custom CSS style template which can be used to further enhance the presentation. For the purpose of this book, the default options should be sufficient. Below is an example knit output of the above RMarkdown file.

The default output above is an html_document format but this format can be modified using, for example, pdf_document to output a pdf. However, the pdf format requires additional installation and configuration of a TeX distribution such as MikTeX. Once available, the user can also include raw LaTeX and even define LaTeX macros in the RMarkdown document if necessary (we’ll discuss more about LaTeX further on).
2.2.1 Subsections
To make your sections numbered as sections and subsections, make sure you specify number_sections: yes as part of the YAML Metadata as shown below.

2.3 Text
Due to its literate nature, text will be an essential part in explaining your analysis. With RMarkdown, we can specify custom text formatting with emphases such as italics, bold, or code style. To understand how to format text, our previous sentence would be typed out as follows in RMarkdown:
With RMarkdown, we can specify custom text formatting with emphases such as *italics*, **bold**, or `code style
2.3.1 Headers
As seen above, headers are preceded by a #. A single # produces the largest heading text while, to produce smaller headings, you simply need to add more #s! Heading level also impacts section and subsection nesting in documents and tables of contents, as well as slide breaks in presentation formats.
2.3.2 Lists
Lists can be extremely convenient to make text more readable or to take course notes during class. RMarkdown allows to create different list structures as shown in the code below:
* You can create bullet points by using symbols such as *, +, or -.
+ simply add an indent or four preceding spaces to indent a list.
+ You can manipulate the number of spaces or indents to your liking.
- Like this.
* Here we go back to the first indent.
1. To make the list ordered, use numbers.
1. We can use one again to continue our ordered list.
2. Or we can add the next consecutive number. which delivers the following list structure:
- You can create bullet points by using symbols such as *, +, or -.
- simply add an indent or four preceding spaces to indent a list.
- You can manipulate the number of spaces or indents to your liking.
- Like this.
- Here we go back to the first indent.
- You can manipulate the number of spaces or indents to your liking.
- To make the list ordered, use numbers.
- We can use one again to continue our ordered list.
- Or we can add the next consecutive number.
2.3.3 Hyperlinks
To add hyperlinks with the full link, (ex: https://google.com/) you can follow the syntax below:
<https://google.com/>whereas to add hyperlinks with a custom link title, (ex: Google) follow the syntax below:
[Google](https://google.com)2.3.4 Blockquotes
Use the > character in front of a line, just like in email to produce blockquotes which styles the text in a way to use if we quote a person, a song or another entity.
“To grow taller, you should shave your head. Remember to bring the towels!”
Justin Lee
2.3.5 Pictures
To add a picture with captions, follow the syntax below:
which will produce:

Otherwise, to add a picture without any captions, follow the syntax below:
which delivers:
2.3.6 LaTeX
LaTeX is a document preparation system that uses plain text as opposed to formatted text that is used for applications such as Microsoft Word. It is widely used in academia as a standard for the publication of scientific documents. It has control over large documents containing sectioning, cross-references, tables and figures.
2.3.6.1 LaTeX in RMarkdown
Unlike a highly formatted word processor, we cannot produce equations by clicking on symbols. As data scientists there is often the need to explain distributions and equations that are behind the methods we present. Within the text section of an RMarkdown document you can include LaTeX format text to output different forms of text, mainly equations and mathematical expressions.
Inline mathematical expressions can be added using the syntax: $math expression$. For example, if we want to write “where \(\alpha\) is in degrees” we would write:
"where $\alpha$ is in degrees".Using a slightly different syntax (i.e. $$math expression$$) we can obtain centered mathematical expressions. For example, the binomial probability distribution in LaTeX is written as
$$f(y|N,p) = \frac{N!}{y!(N-y)!}\cdot p^y \cdot (1-p)^{N-y} = {{N}\choose{y}} \cdot p^y \cdot (1-p)^{N-y}$$
which is output as:
\[f(y|N,p) = \frac{N!}{y!(N-y)!}\cdot p^y \cdot (1-p)^{N-y} = {{N}\choose{y}} \cdot p^y \cdot (1-p)^{N-y}\]
An introduction to the LaTeX format can be found here if you want to learn more about the basics. An alternative can be to insert custom LaTeX formulas using a graphical interface such as codecogs.
2.3.7 Cross-referencing Sections
You can also use the same syntax \@ref(label) to reference sections, where label is the section identifier (ID). By default, Pandoc will generate IDs for all section headers, e.g., # Hello World will have an ID hello-world. To call header hello-world as a header, we type \@ref(hello-world) to cross-reference the section. In order to avoid forgetting to update the reference label after you change the section header, you may also manually assign an ID to a section header by appending {#id} to it.
2.3.8 Citations and Bibliography
Citations and bibliographies can automatically be generated with RMarkdown. In order to use this feature we first need to create a “BibTex” database which is a simple plain text file (with the extension “.bib”) where each reference you would like to cite is entered in a specific manner.
To illustrate how this is done, let us take the example of a recent paper where two researchers from Oxford University investigated the connection between the taste of food and various features of cutlery such as weight and color (calling this phenomenon the “taste of cutlery”). The BibTeX “entry” for this paper is given below:
@article{harrar2013taste,
title={The taste of cutlery: how the taste of food is affected by the weight, size,
shape, and colour of the cutlery used to eat it},
author={Harrar, Vanessa and Spence, Charles},
journal={Flavour},
volume={2},
number={1},
pages={21},
year={2013},
publisher={BioMed Central}
}This may look like a complicated format to save a reference but there is an easy way to obtain this format without having to manually fill in the different slots. To do so, go online and search for “Google Scholar” which is a search engine specifically dedicated to academic or other types of publications. In the latter search engine you can insert keywords or the title and/or authors of the publication you are interested in and find it in the list of results. In our example we search for “The taste of cutlery” and the publication we are interested in is the first in the results list.
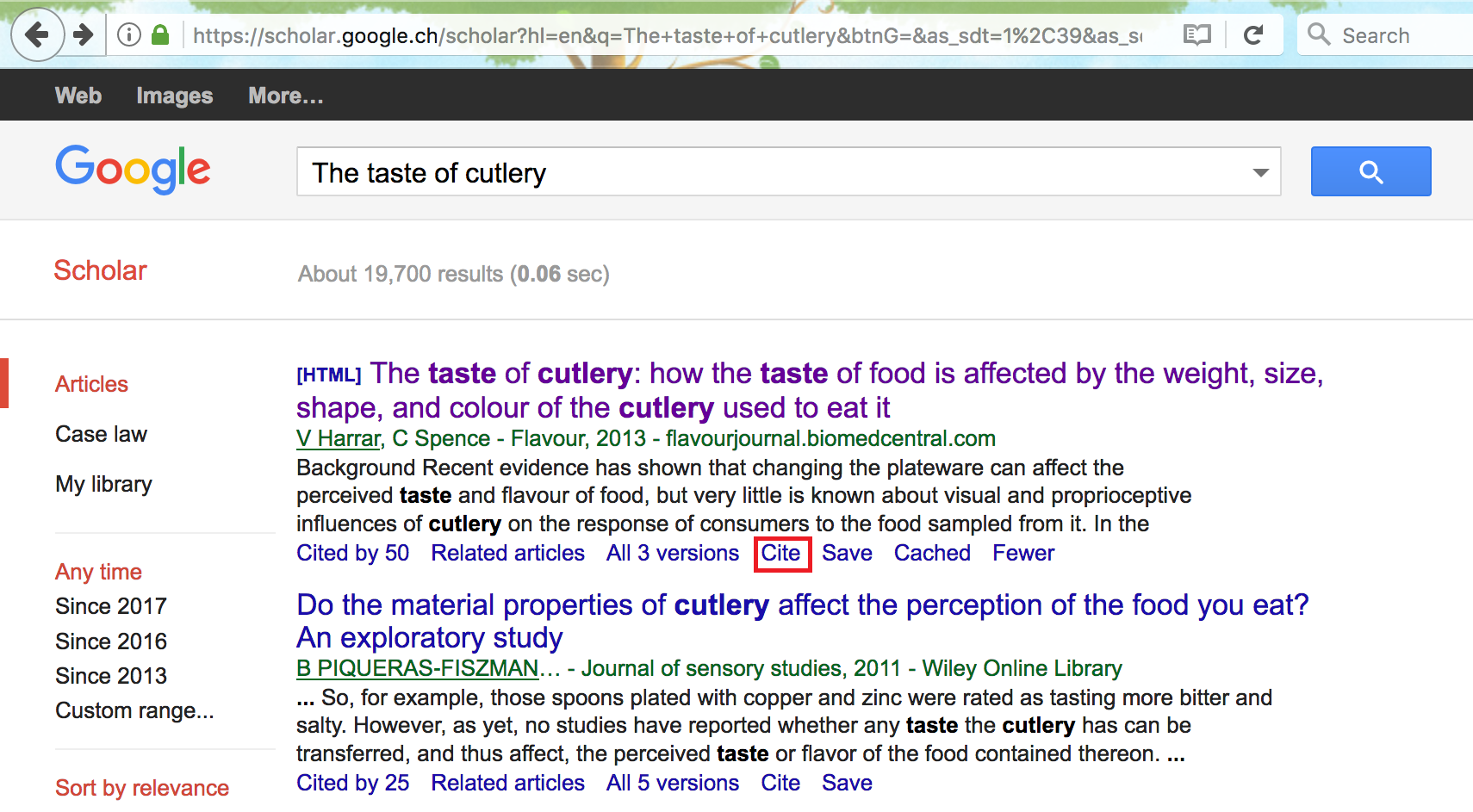
Below every publication in the list there is a set of options among which the one we are interested in is the “Cite” option that should open a window in which a series of reference options are available. Aside from different reference formats that can be copied and pasted into your document, at the bottom of the window you can find another set of options (with related links) that refer to different bibliography managers.
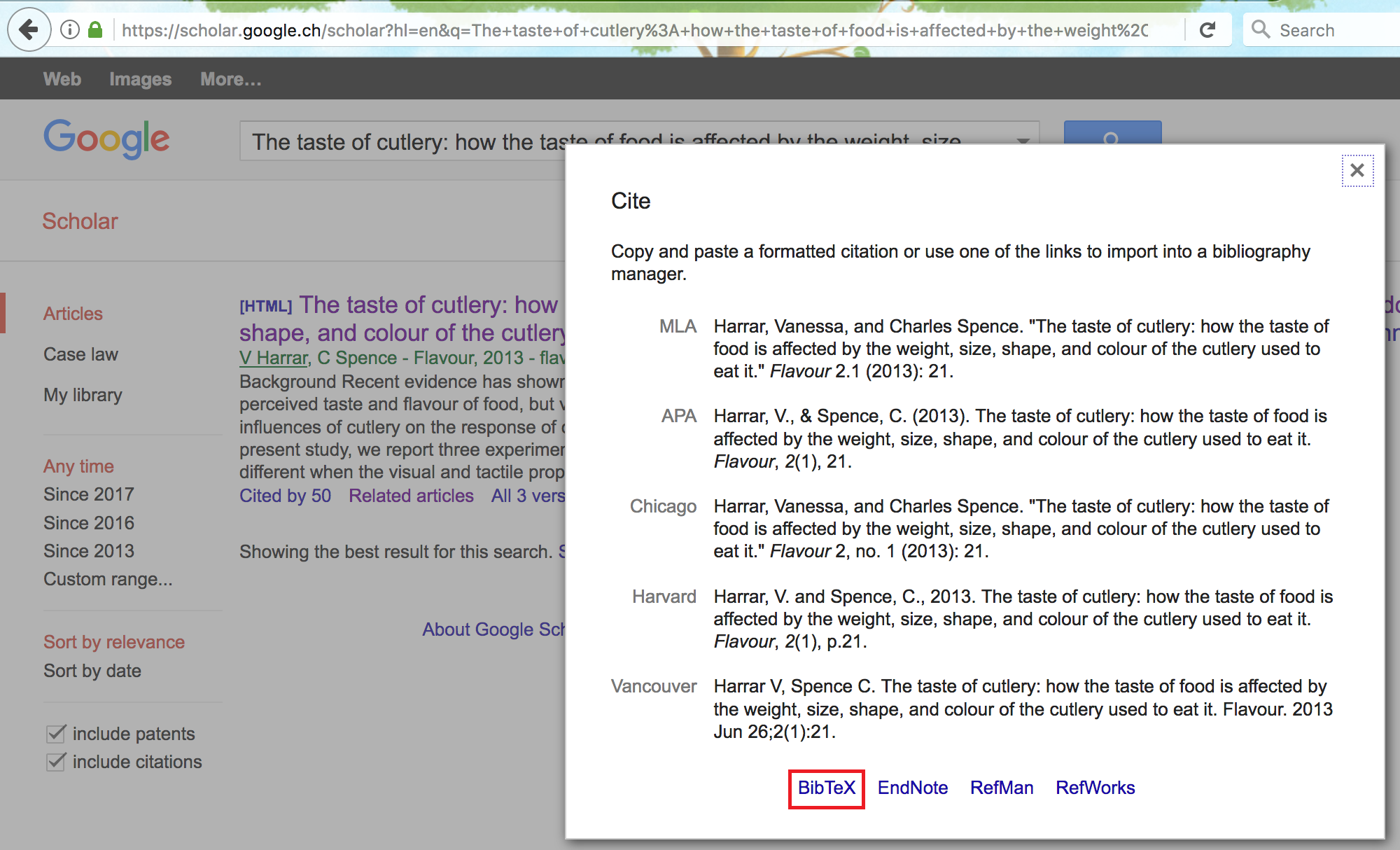
For “.bib” files we are interested in the “BibTeX” option and by clicking on it we will be taken to another tab in which the format of the reference we want is provided. All that needs to be done at this point is to copy this format (that we saw earlier in this section) and paste in the “.bib” file you created and save the changes.

However, your RMarkdown document does not know about the existence of this bibliography file and therefore we need to insert this information in the YAML metadata at the start of our document. To do so, let us suppose that you named this file “biblio.bib” (saved in the same location as your RMarkdown document). All that needs to be done is to add another line in the YAML metadata with bibliography: biblio.bib and your RMarkdown will now be able to recognize the references within your “.bib” file.
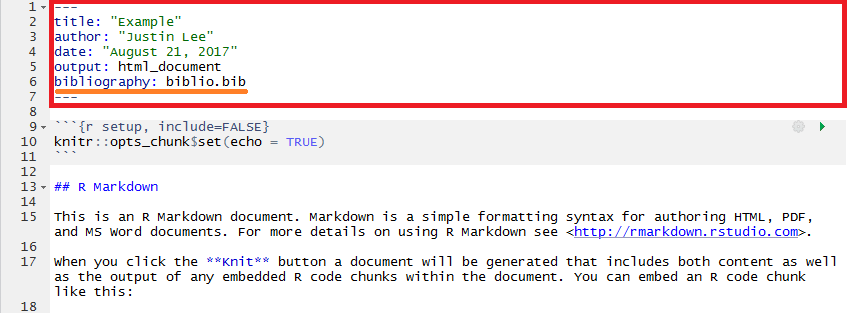
There are also a series of other options that can be specified for the bibliography such as its format or the way references can be used within the text (see links at the end of this section).
Once the “.bib” file has been created and has been linked to your RMarkdown document through the details in the YAML metadata, you can now start using the references you have collected in the “.bib” file. To insert these references within your document at any point of your text you need to use the name that starts the reference field in your “.bib” file and place it immediately after the @ symbol (without spaces). So, for example, say that we wanted to cite the publication on the “taste of cutlery”: in your RMarkdown all you have to do is to type @harrar2013taste at the point where you want this citation in the text and you will obtain: Harrar and Spence (2013). Moreover, it is often useful to put a citation in braces and for example if you want to obtain (see e.g. Harrar and Spence 2013) you can simply write [see e.g. @harrar2013taste].
Additional information on BibTeX and reference in RMarkdown can be found in the links below:
2.3.9 Tables
For simple tables, we can be manually insert values as such follows:
+---------------+---------------+--------------------+
| Fruit | Price | Advantages |
+===============+===============+====================+
| *Bananas* | $1.34 | - built-in wrapper |
| | | - bright color |
+---------------+---------------+--------------------+
| Oranges | $2.10 | - cures scurvy |
| | | - **tasty** |
+---------------+---------------+--------------------+to produce:
| Fruit | Price | Advantages |
|---|---|---|
| Bananas | $1.34 |
|
| Oranges | $2.10 |
|
As an alternative we can use the simple graphical user interface online. For more extensive tables, we create dataframe objects and project them using knitr::kable() which we will explain later on this book.
2.3.10 Additional References
There are many more elements to creating a useful report using RMarkdown, and we encourage you to use the RMarkdown Cheatsheet as a reference.
2.4 Code Chunks
Code chunks are those parts of the RMarkdown document where it is possible to embed R code within your output. To insert these chunks within your RMarkdown file you can use the following shortcuts:
- the keyboard shortcut Ctrl + Alt + I (OS X: Cmd + Option + I)
- the Add Chunk command in the editor toolbar
- by typing the chunk delimiters ```{* and ```**.
The following example highlights the code chunks in the example RMarkdown document we saw at the start of this chapter:
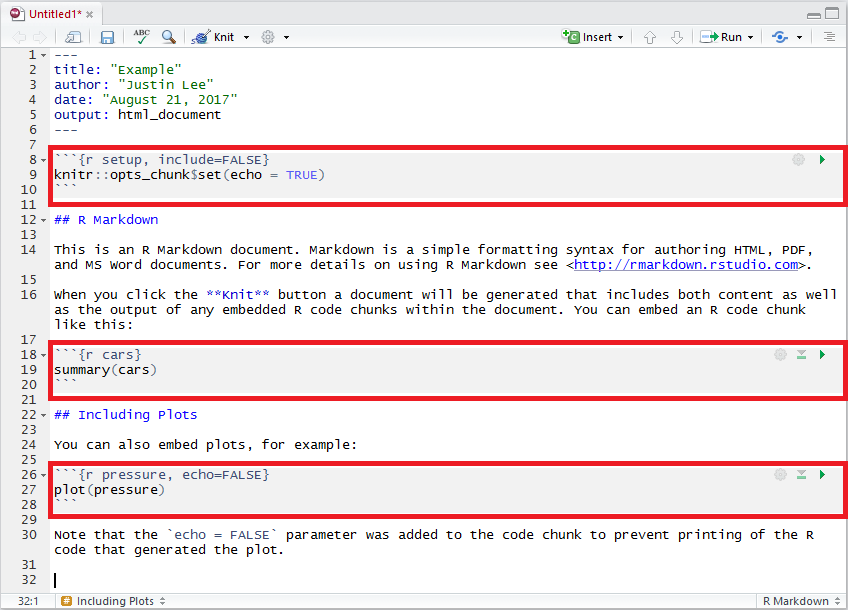
2.4.1 Code Chunk Options
A variety of options can be specified to manage the code chunks contained in the document. For example, as can be seen in the third code chunk in the example above, we specify an argument that reads echo = FALSE which is a parameter that was added to the code chunk to prevent printing the R code that generated the plot. This is a useful way to embed figures. More options can be found from the RMarkdown Cheatsheet and Yihui’s notes on knitr options. Here are some explanations of the most commonly used chunk options taken from these references:
eval: (TRUE; logical) whether to evaluate the code chunk;echo: (TRUE; logical or numeric) whether to include R source code in the output file;warning: (TRUE; logical) whether to preserve warnings (produced by warning()) in the output like we run R code in a terminal (if FALSE, all warnings will be printed in the console instead of the output document);cache: (FALSE; logical) whether to “cache” a code chunk. This option is particularly important in practice and is discussed in more details in Section 2.4.4.
Plot figure options:
fig.path: (‘figure/’; character) prefix to be used for figure filenames (fig.path and chunk labels are concatenated to make filenames);fig.show: (‘asis’; character) how to show/arrange the plots;fig.width,fig.height: (both are 7; numeric) width and height of the plot, to be used in the graphics device (in inches) and have to be numeric;fig.align: (‘default’; character) alignment of figures in the output document (possible values are left, right and center;fig.cap: (NULL; character) figure caption to be used in a figure environment.
2.4.3 In-line R
The variables we store in an RMarkdown document will stay within the environment they were created in. This means that we can call and manipulate them anywhere within the document. For example, supposing we have a variable called x to which we assign a specific value, then in RMarkdown we can reference this variable by using r x: this will affix the value of the variable directly in a sentence. Here is a practical example:
where we have stored the value 2 in a variable called a. We can use the value of a as follows:
The value of $a$ is `r a`. This translates in R Markdown to “The value of \(a\) is 2.”
2.4.4 Cache
Depending on the complexity of calculations in your embedded R code, it may be convenient to avoid re-running the computations (which could be lengthy) each time you knit the document together. For this purpose, it possible to specify an additional argument for your embedded R code which is the cache argument. By default this argument is assigned the value FALSE and therefore the R code is run every time your document is compiled. However, if you specify this argument as cache = TRUE, then the code is only run the first time the document is compiled while the following times it simply stores and presents the results of the computations when the document was first compiled.
Below is a short video introducing caching in R Markdown.
The RMarkdown file used for this particular example can be found here: caching.Rmd.
Let us consider an example where we want to embed an R code with a very simple operation such as assigning the value of 2 to an object that we call a (that we saw earlier). This is clearly not the best example since this operation runs extremely quickly and there is no visible loss in document compilation time. However, we will use it just to highlight how the cache argument works. Therefore, if we want to avoid running this operation each time the document is compiled, then we just embed our R code as follows:
which would be written in RMarkdown as:
You will notice that we called this chunk of embedded R code computeA and the reason for this will become apparent further on. Once we have done this we can compile the document that will run this operation and store its result. Now, if we compile the document again (independently from whether we made changes to the rest of the document or not) this operation will not be run and the result of the previous (first) compiling will be presented. However, if changes are made to the R code which has been “cached”, then the code will be run again and this time its new result will be stored for all the following compilings until it is changed again.
This argument can therefore be very useful when computationally intensive R code is embedded within your document. Nevertheless it can suffer from a drawback which consists in dependencies of your “cached” R code with other chunks within the document. In this case, the other chunks of R code can be modified thereby outputting different results but these will not be considered by your “cached” R code. As an example, suppose we have another chunk of R code that we can “cache” and that takes the value of a from the previous chunk:
## [1] 4which would be written in RMarkdown as:
In this case, the output of this chunk will be ## 4 since a <- 2 (from the previous chunk). What happens however if we modify the value of a in the previous chunk? In this case, the previous chunk will be recomputed but the value of d (in the following chunk) will not be updated since it has stored the value of 4 and it is not recomputed since this chunk has not been modified. To avoid this, a solution is to specify the chunks of code that the “cached” code depends on. This is why we initially gave a name to the first chunk of code (“computeA”) so as to refer to it in following chunks of “cached” code that depend on it. To refer to this code you need to use the option dependson as follows:
## [1] 4which we would write as:
In this manner, if the value of a changes in the first chunk, the value of d will also change but will be stored until either the computeA chunk or the latter chunk is modified.
2.5 Render Output
After you are done, run RMarkdown::render() or click the Knit button at the top of the RStudio scripts pane to save the output in your working directory.
The use of RMarkdown makes it possible to generate any file format such as HTML, pdf and Word processor formats using pandoc. Pandoc is a free software that understands and converts useful markdown syntax, such as the code mentioned above, into a readable and clean format.
2.6 Addition Information
Click on the links below for more information on RMarkdown:
A Basic Probability and Statistics with R
Harrar, Vanessa, and Charles Spence. 2013. “The Taste of Cutlery: How the Taste of Food Is Affected by the Weight, Size, Shape, and Colour of the Cutlery Used to Eat It.” Flavour 2 (1): 21.
2.4.2 Comments
Adding comments to describe the code is extremely useful (if not essential) during every coding and programming process. It helps you take notes and remember what is going on and why you made use of these functions, as well as helping others understand your code. Forgetting to comment or document your code often becomes a larger problem in the future when, among numerous lines of code, you have forgotten the reason for using certain functions or algorithms.